从目标检测到语义分割
目标检测方法可以帮助我们绘制某些确定实体的边框,但人类对场景的理解能以像素级的精细程度对每一个实体进行检测并标记精确的边界。我们已经开始发展自动驾驶汽车和智能机器人,这些都需要深入理解周围环境,因此精确分割实体变得越来越重要。
语义分割是计算机视觉中的基本任务,在语义分割中我们需要将视觉输入分为不同的语义可解释类别,「语义的可解释性」即分类类别在真实世界中是有意义的。例如,我们可能需要区分图像中属于汽车的所有像素,并把这些像素涂成蓝色。

虽然像聚类这样的无监督方法可以用于分割,但其结果不一定是有语义的。与图像分类或目标检测相比,语义分割使我们对图像有更加细致的了解。这种了解在诸如自动驾驶、机器人以及图像搜索引擎等许多领域都是非常重要的。
我们知道,在做图像分类的时候,一般会在模型的最后添加全连接层+softmax用于预测。但是,全连接层会把卷积学习到的类别,位置特征抽象成一维的概率信息,可以识别整个图片的类别,不能标识每个像素的类别。因此,为了保留图像特征我们将全连接层替换为卷积层。
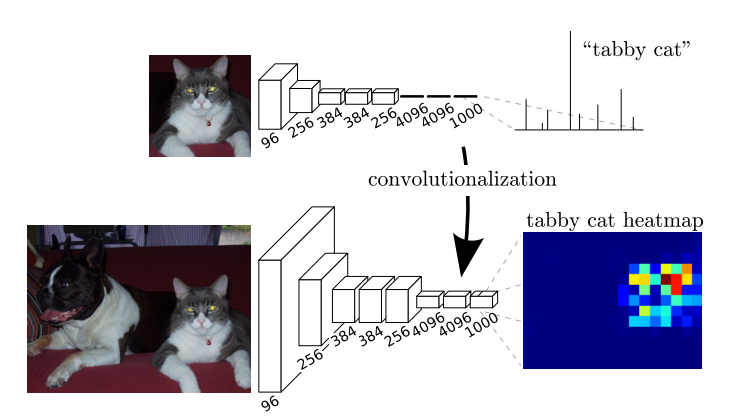
这样,模型的输出不再是一维,而是二维的图。
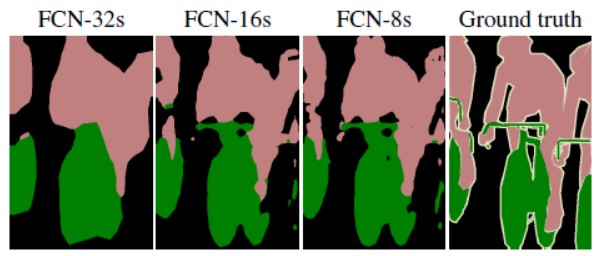
由于特征图经过一系列的卷积和池化后(保持特征不变性,增大感受野,节省计算资源等)造成分辨率降低,丢失大量细节和边缘信息,因此我们需要通过一定的手段还原原图分辨率。不同的模型会采取不同的还原方式,FCN使用了上采样。例如经过5次卷积(和pooling)以后,图像的分辨率依次缩小了2、4、8、16、32倍。对于最后一层的输出图像,需要进行32倍的上采样,以得到原图一样的大小。
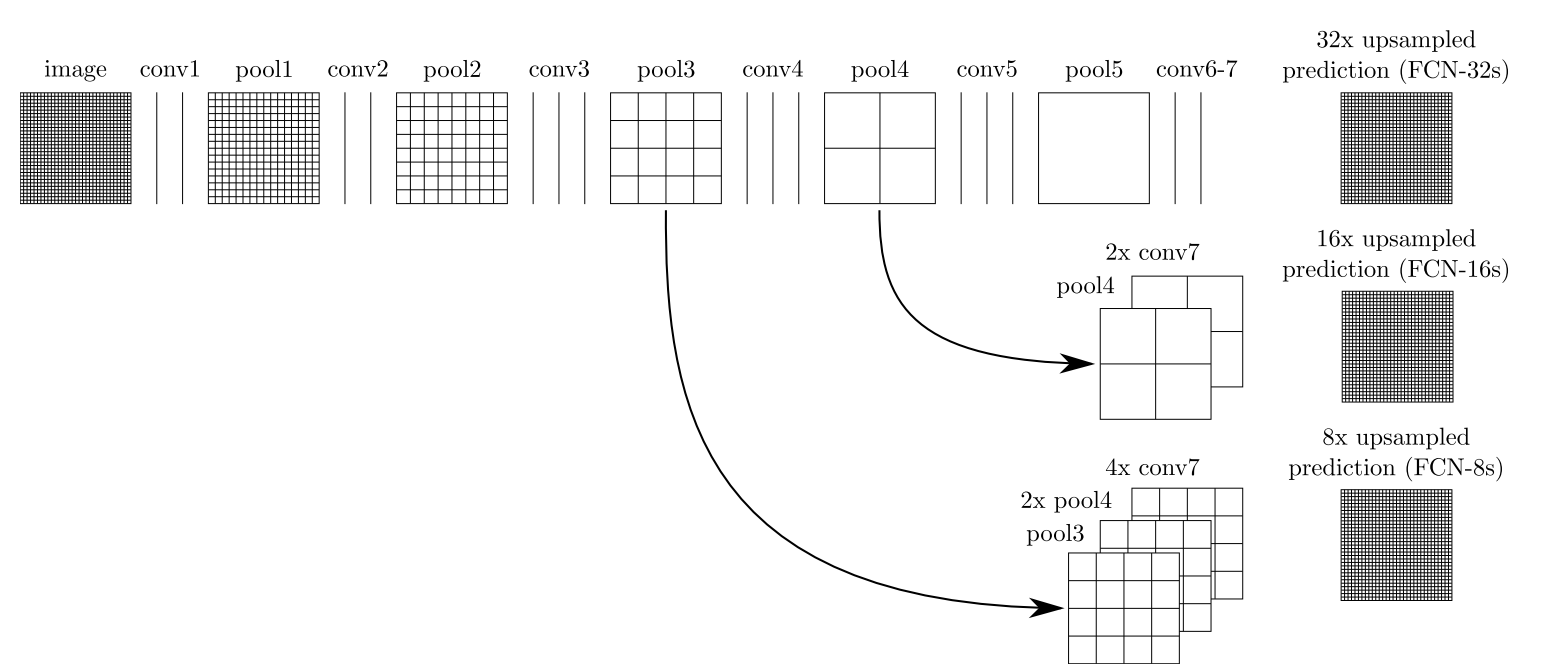
这个上采样是通过反卷积(deconvolution)实现的。对第5层的输出(32倍放大)反卷积到原图大小,得到的结果不够精确,一些细节无法恢复。对第4层的输出和第3层的输出也依次反卷积,分别需要16倍和8倍上采样,结果就精细一些了。下图是32倍、16倍和8倍上采样得到的结果的对比,可以看到它们得到的结果越来越精确: