Agent Memory到底在给谁做?人本位 or 模型本位
人本位的Agent Memory:知识工程
以 Mem0、MemU、Zep 为代表的主流记忆方案,是典型的人本位记忆,核心假设是记忆应该像人类的知识管理一样,有明确的分类、层级和语义关联由人预先定义记忆的结构、粒度、索引方式,把记忆系统做成一个可控、可解释、可管理的检索系统,其核心目标其实是导向人类:追求可解释、可审计、可可视化、可手动编辑,方便产品落地与调试。
也就是说,其假设Agent需要像人类一样拥有一个外部世界模型,记忆=对世界实体的表征(representation),目标是复现人类认知结构(概念、关系、层级),检索=在这个外部模型中定位相关信息,本质上是符号主义AI的延续,只是用LLM做了抽取器和编码器。
先说这类方案的典型特征。
其一,人工在结构上进行先验规定,定义实体、关系、事件、摘要、洞察、偏好等记忆结构,把对话与行为拆解为人类易于理解的单元;
其二,重结构化工程,依赖实体抽取、关系抽取、摘要生成、主题聚类、层级树、知识图谱这些抽取化的流程,索引很重,很费Token;
其三,混合索引体系,采用向量检索 + 关键词检索 + 时间衰减 + 权重打分 + 层级路由,层层封装;
而也就是这种设定,也就自然会带来优劣势之分。
优势很直观,高度可控,记忆内容、结构、召回逻辑完全在人类掌控中;可解释性强,可审计,能清晰看到 Agent“记住了什么、怎么记住的、为何 recalled”,对于对企业级场景、合规需求、固定任务对话很实用。
但为了实现这种优势,损失了一些代价,它看似是Agent记忆,本质只是外挂式RAG的升级版【也就是常说的RAG并没有死,它只不过化作了Agen t的memory】,这就导致了一个问题需要思考?
这是否存在存在严重的人类偏见?人认为重要的结构,模型未必需要? 抽取、归一化、一致性维护、冲突消解成本极高,这种工程沉重其实带来了很多token的消耗?还会损失记忆?
此外,有个点其实是存在的,以人为本位的记忆系统存在一个可控的幻觉,可以看到图谱、可以编辑节点、可以管理索引,但这种可控性建立在两个脆弱假设上,一个是抽取的保真度,LLM 抽取的实体/关系真的准确吗?一个是结构的稳定性,今天合理的分类,明天交互上下文变了,结构是否还成立?
人本位的这种memory系统只是把模型的不确定性转移到了工程系统的复杂性中,获得了可视化的控制面板,但底层仍然是黑盒模型的输出。
模型本位的Agent Memory:Transformer
模型本位记忆系统则是Claude Code风格,使用Markdown、轻量、动态渐进式披露、压缩、上下文内管理,其核心假设是—LLM本身足够聪明,不需要人类式的复杂索引结构,只要给模型足够的上下文和压缩能力,有意义的结构会自然浮现,而不需要人类预先定义结构。

Claude Code的记忆很简单,可以概括为:上下文即记忆,压缩即遗忘,加载即回忆,通过控制什么留在上下文中、什么被压缩丢弃,让模型在有限的注意力窗口里始终”刚好够用” 。
其核心做的其实是压缩,而非通过结构化的方式去做。

第一层BudgetReduction,截断超长输出,单个工具返回超过阈值(如日志、文件内容)时,直接截断保留首尾,中间用…(truncated)…替代。不触发模型推理,纯文本硬切割。
第二层Snip,丢弃过期交互,按时间深度淘汰,超过N轮的旧对话整轮删除。N动态调整,确保剩余内容+当前请求不超过总预算。被删轮次不留痕迹,彻底消失;
第三层Microcompact,合并同类操作,检测相邻的同类工具调用(如连续多次read_file、grep),合并为一个摘要块,保留输入参数和最终结论,省略中间过程。减少token数但保留操作意图;
第四层ContextCollapse,折叠早期会话,将多轮早期对话压缩为单行人类可读摘要(如”用户要求重构路由,已讨论三种方案,选定方案B”)。保留决策结果和关键上下文,丢弃推理过程和已否决选项。
第五层Auto-compact,语义重写压缩,调用模型自身对历史进行语义摘要重写,用更紧凑的表达替代原始对话。有损程度最高,可能丢失语气、细节和边缘信息,但保留核心语义。最后手段,仅在前面四级仍不足时触发。
在记忆流转上,也适用轻量化的方式在做,如下:
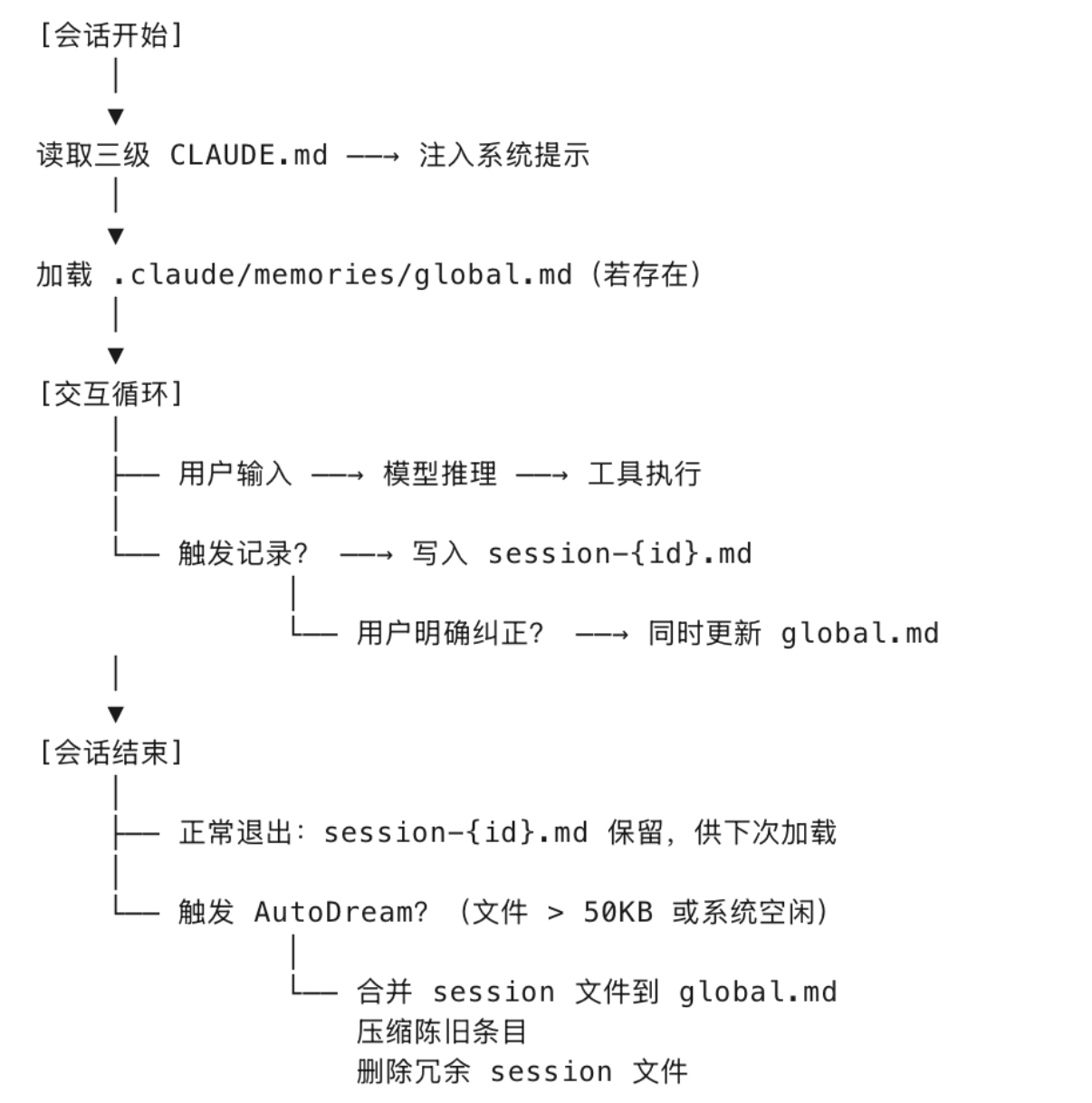
整体看来,好像没啥毛病,但既然如此牛逼?为啥大家还去折腾“人本位”?可能有以下考量:
其一,Claude Code这种的轻量化记忆轻量,高度依赖底层模型的能力补偿,长上下文窗口(200K),指令遵循强,CLAUDE.md 的规则能被稳定执行,上下文能力理解能力强,可以从压缩后的摘要中重建决策逻辑,换成其他的模型可能并不好用,看不太懂。
其二,这种”并非真的”无结构”,而是结构隐式化,Claude Code 的 Markdown 驱动看似无结构,实则利用了LLM对标记语言(Markdown)的天然理解能力,标题层级、列表、代码块对模型来说就是隐式的树结构。它把”索引”和”路由”的工作交给了模型的上下文理解能力,而不是外部检索系统。其实是把复杂度从工程系统转移到了模型能力上。
其三,”模型本位”这种也有代价,可解释性下降**,当记忆管理完全交给模型压缩时,你很难知道它”记住了什么、忘记了什么”,确定性降低,同样的上下文,不同模型/温度下可能产生不同的记忆重构,成本与延迟,全上下文处理在长程场景下并不经济。