训练集、测试集、验证集与划分方法
一、训练集、测试集、验证集
在机器学习预测任务中,我们需要对模型泛化误差进行评估,选择最优模型。如果我们把所有数据都用来训练模型的话,建立的模型自然是最契合这些数据的,测试表现也好。但换了其它数据集测试这个模型效果可能就没那么好了。为了防止过拟合,就需要将数据集分成训练集、验证集、测试集。
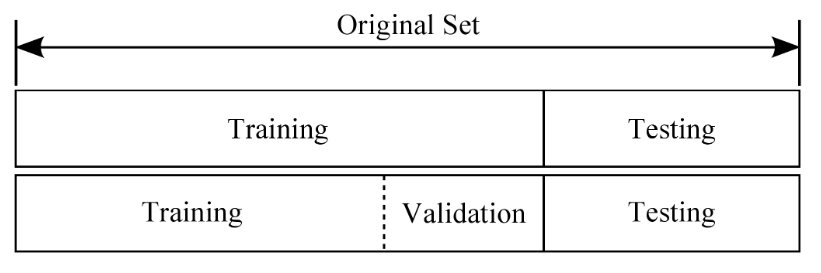
它们的作用分别是:
- 训练集:用来训练模型
- 验证集:评估模型预测的好坏及调整对应的参数
- 测试集:测试已经训练好的模型的推广能力
有一个比喻十分形象,训练集就像高三学生的练习册,验证集就像高考模拟卷,测试集就是最后真正的考试。
如何选择训练集、验证集、测试集的划分比例?
在传统的机器学习中,这三者一般的比例为training/validation/test = 50/25/25,但是有些时候如果模型不需要很多调整只要拟合就可时,或者training本身就是training+validation(比如cross validation)时,也可以training/test =7/3。
二、划分方法
1、留出法(hold-out)
留出法是最简单的数据集划分方式,即将样本按比例分割,对应的函数是train_test_split
1 | import numpy as np |
然而这种方式并不是很好,有两大缺点:一是浪费数据,二是容易过拟合且矫正方式不方便
2、交叉验证法(cross validation)
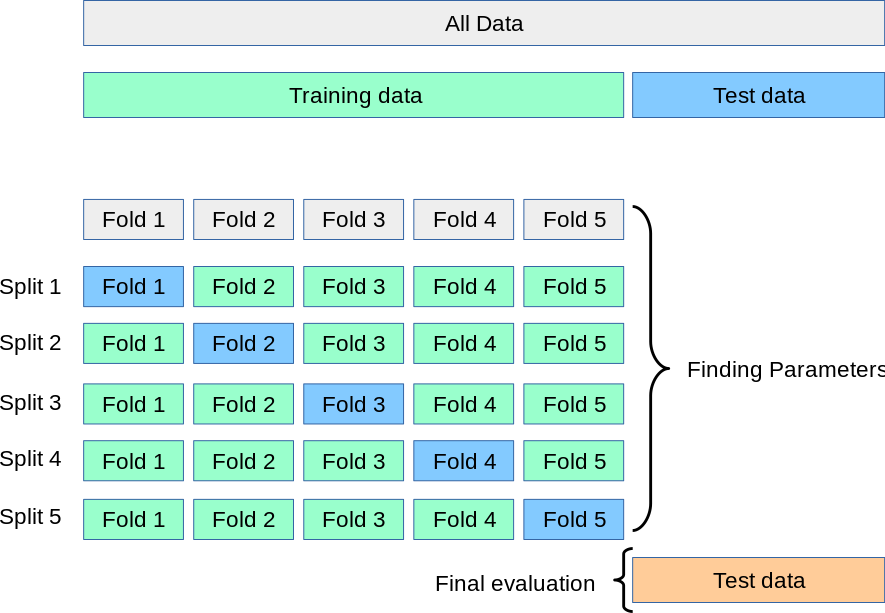
交叉验证法先将数据集D分成k份,每次随机的选择k-1份作为训练集,剩下的1份做验证集。当这一轮完成后,重新随机选择k-1份来训练数据。进行k次训练后,最终返回k个验证结果的均值。因此又称为”k折交叉验证”
数据量大的时候,k可以设置的小一些;数据量小的时候,k可以设置的大一些。
(1)K-Fold
K-Fold是最简单的K折交叉验证。
1 | import numpy as np |
(2)StratifiedKFold
StratifiedKFold用法类似Kfold,但是它是分层采样,确保训练集、验证集中各类别样本的比例与原始数据集中相同。
1 | import numpy as np |
(3)GroupKFold
这个跟StratifiedKFold比较像,不过数据集是按照一定分组进行打乱的,即先分堆。
1 | import numpy as np |
(4)ShuffleSplit
随机排列交叉验证,生成一个用户给定数量的独立的数据划分,样例首先被打散然后划分为一对数据集合。
ShuffleSplit可以替代KFold,因为其提供了细致的数据集划分控制。
1 | import numpy as np |
3、留一法(leave-one-out,LOO)
留一法是k折交叉验证的特殊情况(k=样本数m),即每次只用一个样本作验证集。该方法计算开销较大。
1 | import numpy as np |
4、自助法(bootstrapping)
自助法以自助采样为基础(有放回采样)。每次随机从数据集D中挑选一个样本,放入D‘中,然后将样本放回D中,重复m次之后,得到了包含m个样本的数据集。
自助法在数据集较小、难以有效划分训练/测试集时很有用。
1 | import numpy as np |