构建复杂模型之集成学习(1)
什么是集成学习
前面介绍了一系列的算法,每个算法有不同的适用范围,例如有处理线性可分问题的,有处理线性不可分问题。在现实世界的生活中,常常会因为“集体智慧”使得问题被很容易解决,那么问题来了,在机器学习问题中,对于一个复杂的任务来说,能否将很多的机器学习算法组合在一起,这样计算出来的结果会不会比使用单一的算法性能更好?这样的思路就是集成学习方法。
严格意义上来说,这不算是一种机器学习算法,而更像是一种优化手段或者策略,它通常是结合多个简单的弱机器学习算法,去做更可靠的决策。有人把它称为机器学习中的“屠龙刀”,非常万能且有效,集成模型是一种能在各种的机器学习任务上提高准确率的强有力技术,集成算法往往是很多数据竞赛关键的一步,能够很好地提升算法的性能。哲学思想为“三个臭皮匠赛过诸葛亮”。拿分类问题举个例,直观的理解,就是单个分类器的分类是可能出错,不可靠的,但是如果多个分类器投票,那可靠度就会高很多。
现实生活中,我们经常会通过投票,开会等方式,以做出更加可靠的决策。集成学习就与此类似。集成学习就是有策略的生成一些基础模型,然后有策略地把它们都结合起来以做出最终的决策。集成学习又叫多分类器系统。
集成方法是由多个较弱的模型集成模型组,一般的弱分类器可以是DT, SVM, NN, KNN等构成。其中的模型可以单独进行训练,并且它们的预测能以某种方式结合起来去做出一个总体预测。该算法主要的问题是要找出哪些较弱的模型可以结合起来,以及如何结合的方法。这是一个非常强大的技术集,因此广受欢迎。
集成算法家族强大,思想多样,但是好像没有同一的术语,很多书本上写得也不一样, 不同的学者有不同的描述方式,最常见的一种就是依据集成思想的架构分为 Bagging ,Boosting, Stacking三种。
集成学习的理论基础
集成学习的理论基础来自于Kearns和Valiant提出的基于PAC(probably approximately correct)的可学习性理论 ,PAC 定义了学习算法的强弱:
弱学习(strongly learnable)算法:识别错误率小于1/2(即准确率仅比随机猜测略高的算法)
强学习(strongly learnable)算法:识别准确率很高并能在多项式时间内完成的算法
在概率近似正确(probably approximately correct, PAC)学习的框架中,一个概念(一个类),如果存在一个多项式的学习算法能够学习它,并且正确率很高,那么就称这个概念是强可学习的。一个概念,如果存在一个多项式的学习算法能够学习它,学习正确率仅比随机猜测略好,那么就称这个概念是弱可学习的。Schapire指出在PAC学习框架下,一个概念是强可学习的充分必要条件是这个概念是弱可学习的。那么对于一个学习问题,若是找到“弱学习算法”,那么可以将弱学习方法变成“强学习算法”。
三种思路
集成学习方法是指组合多个模型,以获得更好的效果,使集成的模型具有更强的泛化能力。对于多个模型,如何组合这些模型,主要有以下几种不同的方法:
- 对多个模型的预测结果进行投票或者取平均值;(个体之间不存在强依赖关系,可以同时生成的并行化方法)——Bagging,减小方差
- 对多个模型的预测结果做加权平均。(个体学习器之间存在强依赖关系,必须串行生成的序列化方法)—– Boosting,减小偏差
- 模型融合,多模型的学习加上再学习——Stacking,改进预测
以上的几种思路就对应了集成学习中的几种主要的学习框架。
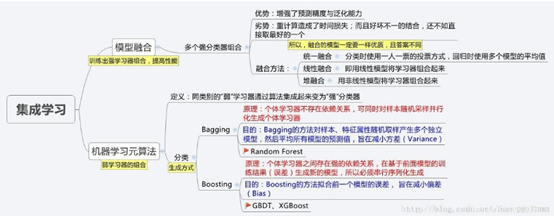
需要注意的是bagging和stacking中的基本模型须为强模型(低偏差高方差),boosting中的基本模型为弱模型(低方差高偏差)。