大模型服务部署架构设计
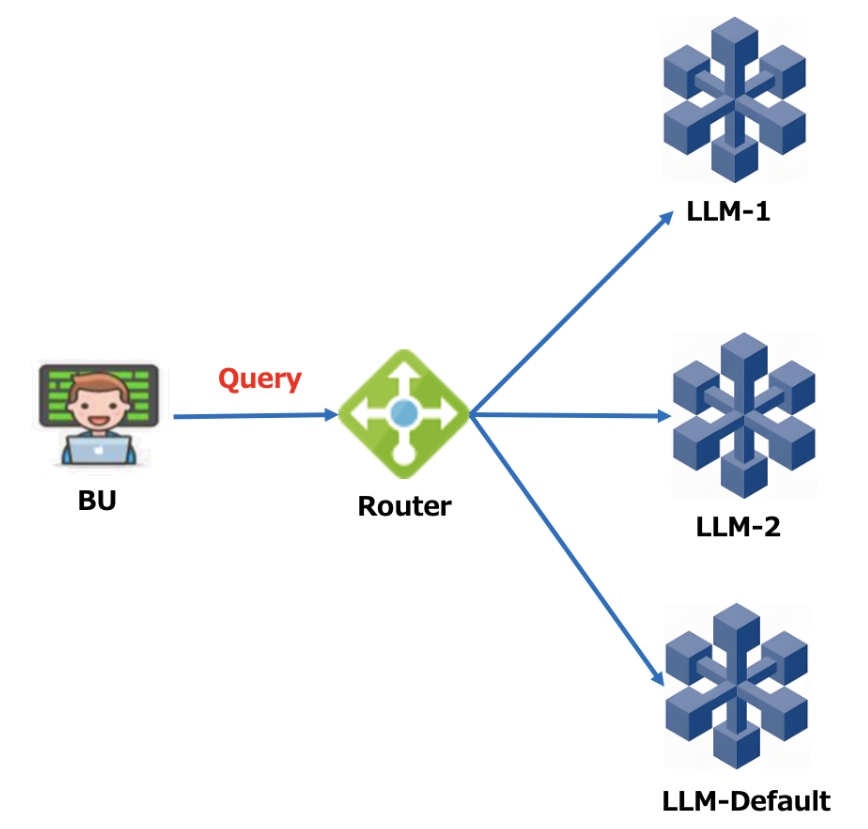
路由选择模式
根据用户query内容,可以明确判断出要路由到哪个大模型。如果根据query内容无法明确,则路由到默认处理的大模型,所以这里需要有一个大模型进行兜底。整体架构上的一个关键点是我们需要封装一个路由模块,可以根据访问意图识别的方式设定路由规则。
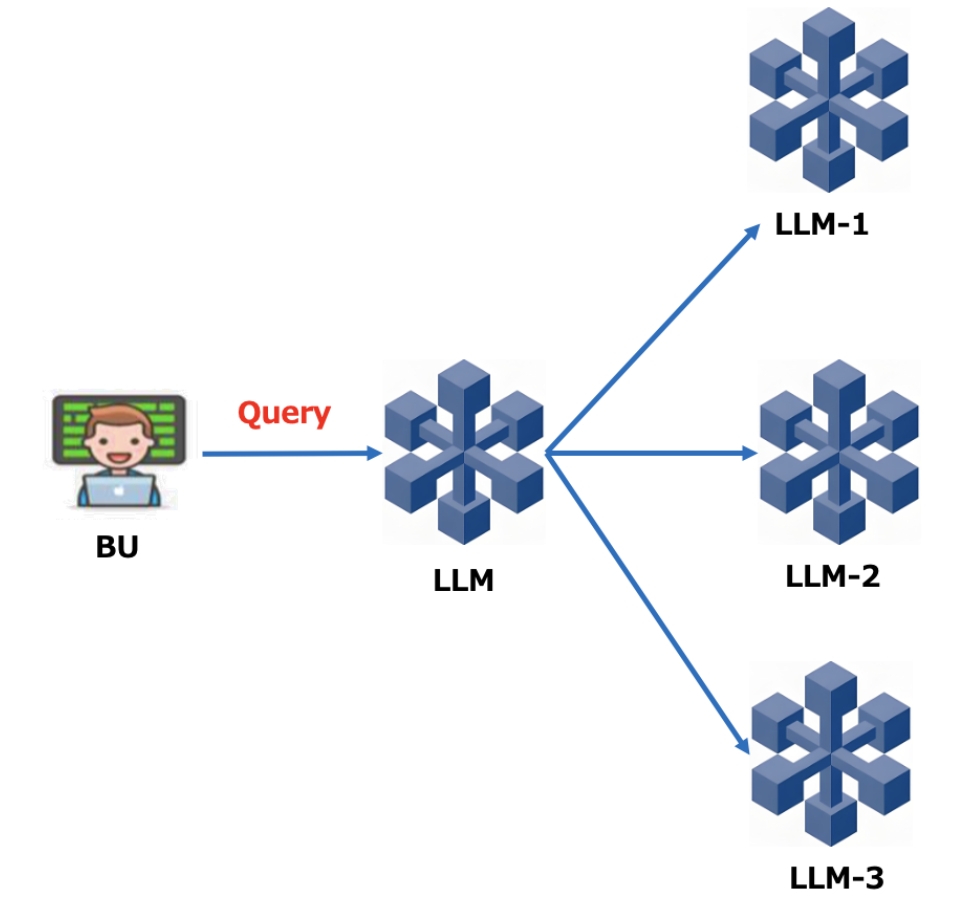
模型代理模式
模型代理模式是上面路由选择模式的一个变种,重要点在于我们把路由模块,换成了用大模型去根据query内容进行分析判断后续调用哪些专属领域的小模型。如果问题较复杂,可能背后同时调用了多个专属业务领域小模型,最后需大模型进行汇总后返回结果。
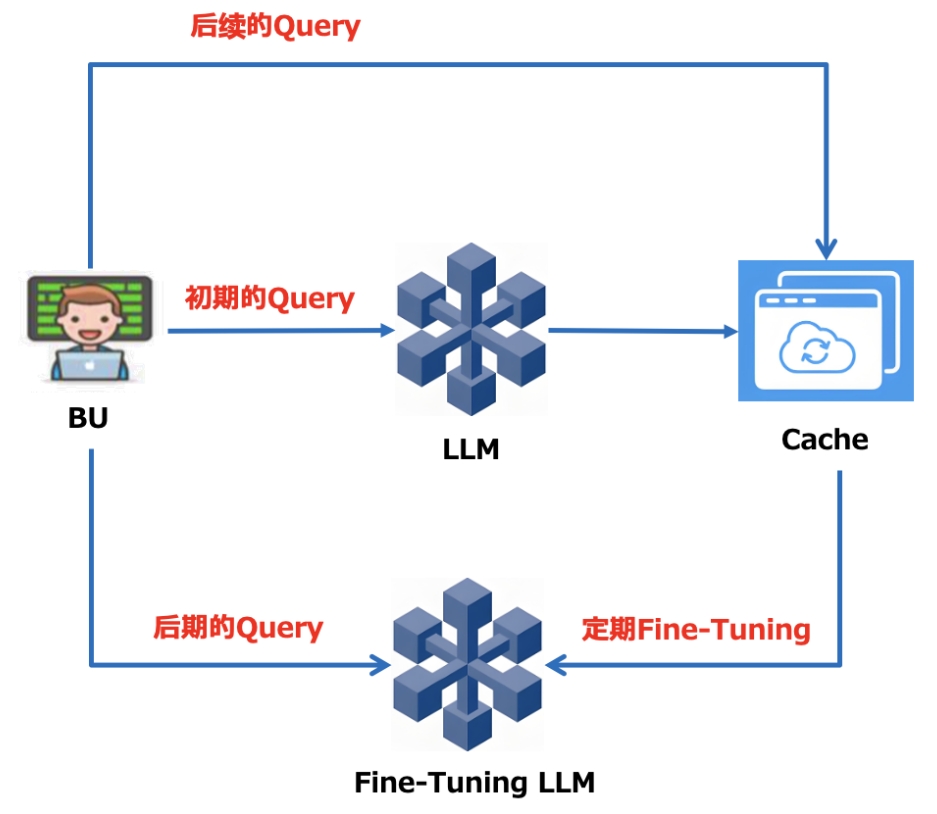
分层缓存模式
这种模式相对复杂一些,加入了缓存的概念。直接从缓存中获取将会大幅提升效率,当缓存中积累了一定数据之后,需要定期进行微调,利用早期交互的反馈,进一步完善一个更为专业化的模型。这里的缓存可以考虑用GPTCache、Cassandra、Redis等。
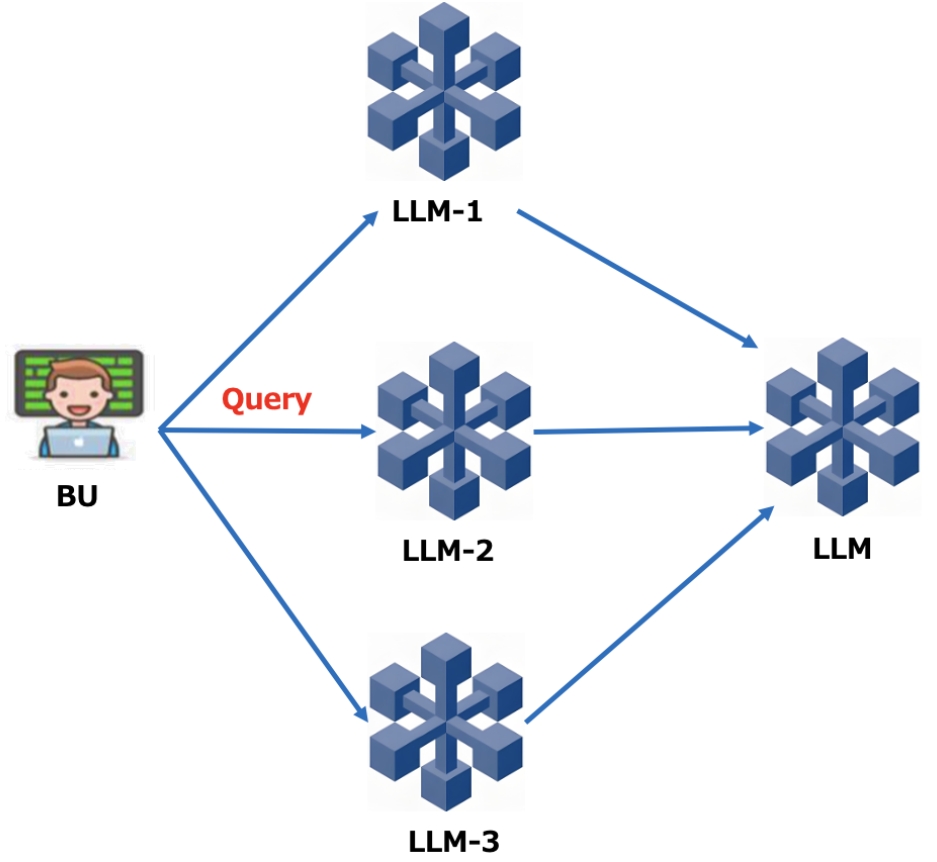
多模型聚合模式
这种模式下是同样的一个query,由多个大模型同时处理和回答,最后结果反馈给一个分析能力强和可处理长Token的大模型,对各个模型反馈的结果进行评估和总结后输出。这种模式下可以说是整合了多个大模型的智慧,超越了任何一个单独大模型达到的效果,可以考虑在需要有大量创新解决方案和处理复杂数据时选择这种模式。
安全双重加固模式
这种模式下主要是对用户的query和大模型输出的结果进行安全加固,这里的安全加固主要是去除一些敏感信息,例如清楚个人的身份信息和知识产权信息等。这里的安全加固层可以考虑封装一个安全加固模块通过定义规则+prompt限定等方式实现。
