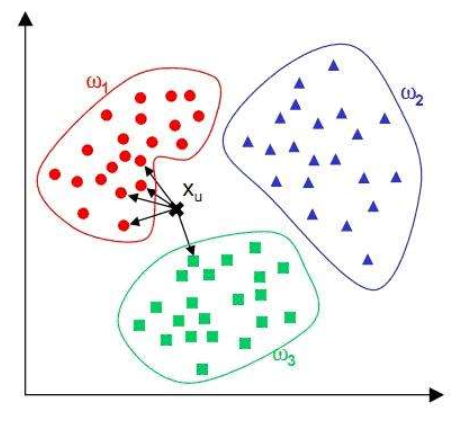
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
| import numpy as np
def KNN(X_train, y_train, X_test, k):
'''
K最近邻方法
遍历测试样本, 计算每个测试样本与训练样本的距离值并排序, 根据前K个投票选举出预测结果
'''
X_train = np.array(X_train)
y_train = np.array(y_train)
X_test = np.array(X_test)
X_train_len = len(X_train)
X_test_len = len(X_test)
pred_labels = []
for test_index in range(X_test_len):
dis = []
for train_index in range(X_train_len):
temp_dis = abs(sum(X_train[train_index,:] - X_test[test_index,:]))**0.5
dis.append(temp_dis)
dis = np.array(dis)
sort_id = dis.argsort()
dic = {}
for i in range(k):
label = y_train[sort_id[i]]
dic[label] = dic.get(label, 0)+1
max = 0
for label, v in dic.items():
if v > max:
max = v
pred_label = label
pred_labels.append(pred_label)
print(pred_labels)
if __name__=="__main__":
X_train = [[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]]
y_train = [1, 2, 3, 1, 2, 3]
X_test = [[1, 2, 3, 4],
[5, 6, 7, 8]]
KNN(X_train,y_train,X_test,2)
|