计算机视觉的几个概念
一、CG、CV、IP
计算机图像学(CG):计算机图形学是一门使用数学算法将二维或三维图形转化为计算机显示器的栅格形式的科学。简单地说,计算机图形学的主要研究内容就是研究如何在计算机中表示图形、以及利用计算机进行图形的计算、处理和显示。
计算机视觉(CV):计算机视觉是一门研究如何使机器”看”的科学,更进一步的说,就是是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理,试图建立能够从图像或者多维数据中获取信息的人工智能系统。
图像处理(IP):在图像科学中,图像处理是用任何信号处理等数学操作处理图像的过程,输入时图像(摄影图像或者视频帧),输出是图像或者与输入图像有关的特征、参数的集合。
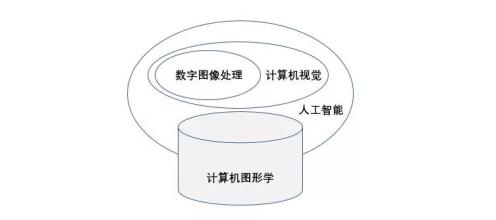
二、CV与机器视觉之间的不同
两者都是与视觉相关,都是通过使用机器或者计算机代替人眼去工作,但是两者的侧重和应用领域有所不同。
机器视觉(machine vision)侧重的是视觉感官上去做人做不到的工作,测量定位这些,与光源镜头自动化控制相关。比如常会用在测量一个硬币的直径、检测产品的损坏与否等相关场景。机器视觉会更注重对视觉上的一个”量”的分析。相关的知识侧重相机镜头光源、图像处理、运动控制等相关。
计算机视觉(computer vision)则更侧重利用计算机分析得到的图像,往往是对图像里面信息的一个分析处理。比如人脸识别、车牌识别、目标跟踪等,更加会侧重的是对视觉的一个”质”的分析。
三、CV在人工智能中的地位
计算机视觉是使用计算机及相关设备对生物视觉的一种模拟。它的主要任务就是通过对采集的图片或视频进行处理以获得相应场景的三维信息,就像人类和许多其他类生物每天所做的那样。由于计算机视觉学在工农业生产、地质学、天文学、气象学、医学及军事并学等领域有着极大的潜在应用价值,所以它在国际上越来越受人重视。
有一种说法认为计算机视觉是人工智能的先导技术。
四、CV面临的主要难点
当前虽然数据量呈现爆炸式增长,但是支撑人工智能发展的两大核心基础:计算能力和算法仍然未取得根本性的突破。从算法上来看,虽然近年来深度学习算法推动人工智能实现了快速发展,但是深度学习的成功不是理论方法上的突破,而是在大数据和大规模计算资源驱动下的基于基础理论的技术突破,这也证明人工智能仍处于一个较为初始的发展阶段。
尽管依靠深度神经网络使计算机视觉技术有了突破,但是它只能解决函数逼近问题,还有很多问题很难用函数逼近去解决。虽说视觉是感知问题,但是视觉背后有很多认知问题,目前主要存在以下几个问题:
(1)定义物体(Functional Object)
物体的定义很难但是又非常重要,如果定义不清楚,就没法做精确的物体识别。同时,还有很多定义的概念是包容性的,千差万别。只有对这些概念有很好的建模,才能做场景理解。
(2)遮挡(Occlusion)
现在的物体检测方法非常非常好了,但遇到遮挡,依然做的不太好。

(3)上下文理解
下图中,两个红框里是什么东西?对于大多数人来讲可能是人,但是机器还没有这个能力去推理出是人。

(4)物体跟踪
下图中,物体的重叠非常严重,人类有很强的跟踪能力,但是如果使用当前最好的跟踪系统,机器也很难做到人类的水平,我们检测方法并没有非常好的推理机制应用到里面。

(5)手眼配合
为什么很多家庭机器人卖不出去?因为现在的机器人做不好手眼配合,它们不能像人类一样能做家务、做饭。
(6)精度问题
不管是做无人车,还是做自动驾驶,在一定程度上要求的精度是非常高的,甚至只有高过现在的标准,人工智能技术才能顺利推广下去。