特征工程(1)
特征工程是机器学习,甚至是深度学习中最为重要的一部分,也是课本上最不愿意讲的一部分,特征工程往往是打开数据密码的钥匙,是数据科学中最有创造力的一部分。有这么一句话在业界广泛流传,数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
那特征工程到底是什么呢?顾名思义,其本质是一项工程活动,目的是最大限度地从原始数据中提取特征以供算法和模型使用。
举一个非常简单的例子,现在出一非常简答的二分类问题题,请你使用逻辑回归设计一个身材分类器,输入数据X为身高和体重,标签为Y为身材等级(胖,不胖)。这里显然不能单纯的根据体重来判断一个人胖不胖,姚明很重,他胖吗?显然不是。针对这个问题,一个非常经典的特征工程是构造BMI指数,BMI=体重/(身高^2)。这样,通过BMI指数就能非常清晰地帮助我们刻画一个人身材如何。甚至,你可以抛弃原始的体重和身高数据。
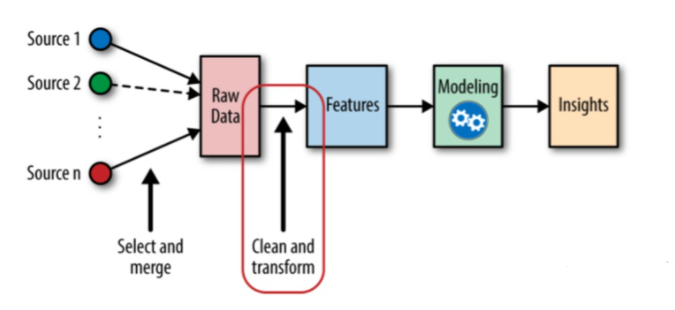
一般来说特征工程可以分为三部分:数据预处理、特征衍生、特征筛选,说起来简单,实际中特征的衍生和筛选都是困难重重的,甚至需要非常专业的专家知识。