半监督学习算法
无监督学习只利用未标记的样本集,而监督学习则只利用标记的样本集进行学习。但在很多实际问题中,只有少量的带有标记的数据,因为对数据进行标记的代价有时很高,比如在生物学中,对某种蛋白质的结构分析或者功能鉴定,可能会花上生物学家很多年的工作,而大量的未标记的数据却很容易得到,这就促使能同时利用标记样本和未标记样本的半监督学习技术迅速发展起来。
一、基本概念
1、有标记样本和未标记样本

在现实任务中,未标记样本多、有标记样本少是一个较为普遍的现象,如何利用好未标记样本来提升模型泛化能力是很有意义的事情。
2、主动学习与半监督学习
用未标记数据的学习技术可以被分成主动学习和半监督学习两类。
(1)主动学习

有的时候,有类标的数据比较稀少而没有类标的数据是相当丰富的,但是对数据进行人工标注又非常昂贵,这时候,学习算法可以主动地提出一些标注请求,将一些经过筛选的数据提交给专家进行标注。
(2)半监督学习
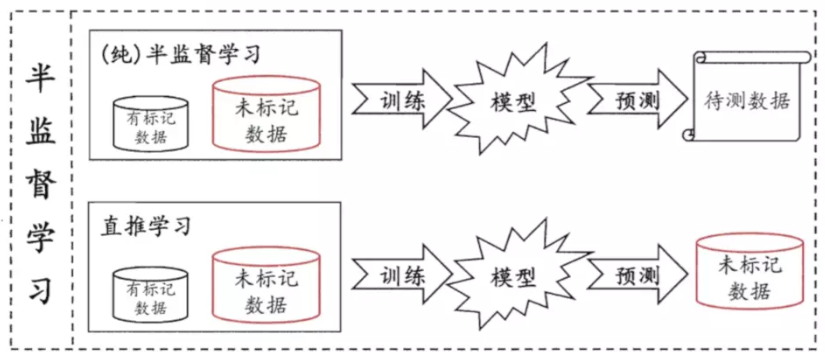
让学习器不依赖外界交互,自动地利用未标记样本来提升学习性能,就是半监督学习(semi-supervised learning,SSL)。
半监督学习可进一步划分为纯半监督学习和直推学习,前者假定训练数据中的未标记样本并非待预测数据,而后者则假定学习过程中所考虑的未标记样本恰是待预测数据,学习的目的就是在这些未标记样本上获得最优泛化性能。换言之,纯半监督学习是基于“开放世界”假设,希望学得模型能适用于训练过程中未观察到的数据;而直推学习是基于“封闭世界”假设,仅试图对学习过程中观察到的未标记数据进行预测。
3、半监督学习的模型假设
半监督学习的成立依赖于模型假设,当模型假设正确时,无类标签的样例能够帮助改进学习性能。最常见的假设是以下两个:
(1)聚类假设
最常见的是聚类假设(cluster assumption),即假设数据存在簇结构,同一个簇的样本属于同一个类别。当两个样例位于同一聚类簇时,它们在很大的概率下有相同的类标签。
低密度分离假设
聚类假设等价定义为低密度分离假设(Low Sensity Separation Assumption),即分类决策边界应该穿过稀疏数据区域,而避免将稠密数据区域的样例分到决策边界两侧。
(2)流形假设
另一个常见假设是流形假设(manifold assumption),即假设数据分布在一个流形结构上,邻近的样本(邻近程度常用相似程度来刻画)拥有相似的输出值。当两个样例位于低维流形中的一个小局部邻域内时,它们具有相似的类标签。
流行假设可看作聚类假设的推广,但流形假设对输出值没有限制,因此比聚类假设的适用范围更广,可用于更多类型的学习任务。
事实上,无论聚类假设还是流形假设,其本质都是”相似的样本拥有相似的输出”这个基本假设。
二、常见的半监督学习算法
