神经网络表格建模工具箱-Kaggle后GBDT时代
如果你在过去十年中参与过Kaggle表格竞赛,你一定会对那个被梯度提升决策树(GBDT)统治的时代记忆犹新——XGBoost、LightGBM、CatBoost 占据了绝大多数解决方案的核心席位。
但技术周期的车轮从未停止。在2024-2025年间,一批全新的深度学习模型,开辟了全新的路径:从参数高效集成、因果先验学习、检索增强推理,到基于注意力的全局关系建模。
TabM
TabM是一个在参数高效集成(Parameter-Efficient Ensembling)思想下构建的、用于处理结构化表格数据的深度学习模型。它在2024年被提出,旨在提升多层感知机在表格数据上的性能与效率。
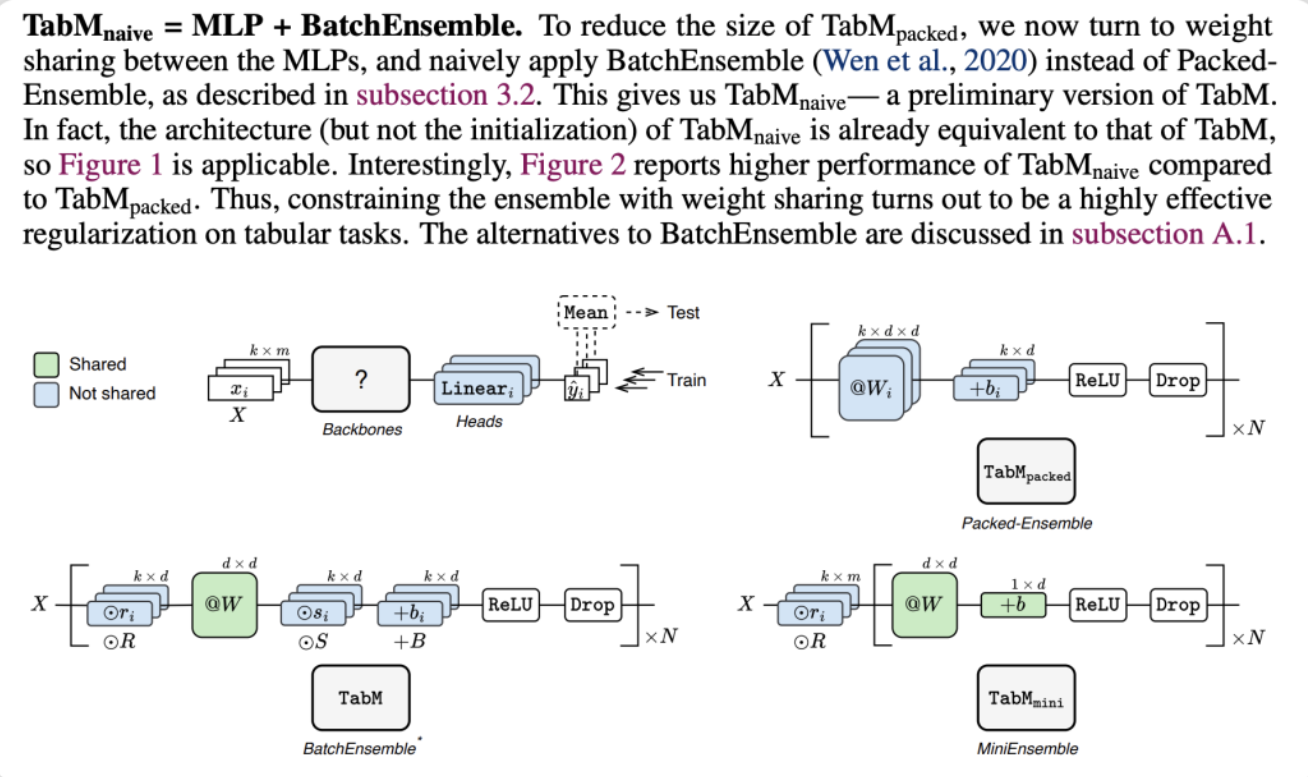
TabM的设计核心是 “用一个模型模仿多个模型” 。它内部融合了许多小型的MLP(多层感知机),这些小模型共享大量权重,同时又有少量独立的参数,从而在显著降低总参数量的情况下,实现传统“模型集成”的效果。
对于同一个输入样本,TabM内部的每个小MLP分支都会独立产生一个预测结果。这些单独的预测可能“较弱”,但它们通过集成(例如取平均或投票)后,会形成一个强大的集体预测。
TabFPN
TabPFN全称为“表格先验数据拟合网络”。它由德国弗莱堡大学的研究团队于2022年首次提出,核心目标是颠覆传统方法,为中小型表格数据提供“开箱即用”、无需专门训练的快速准确预测。
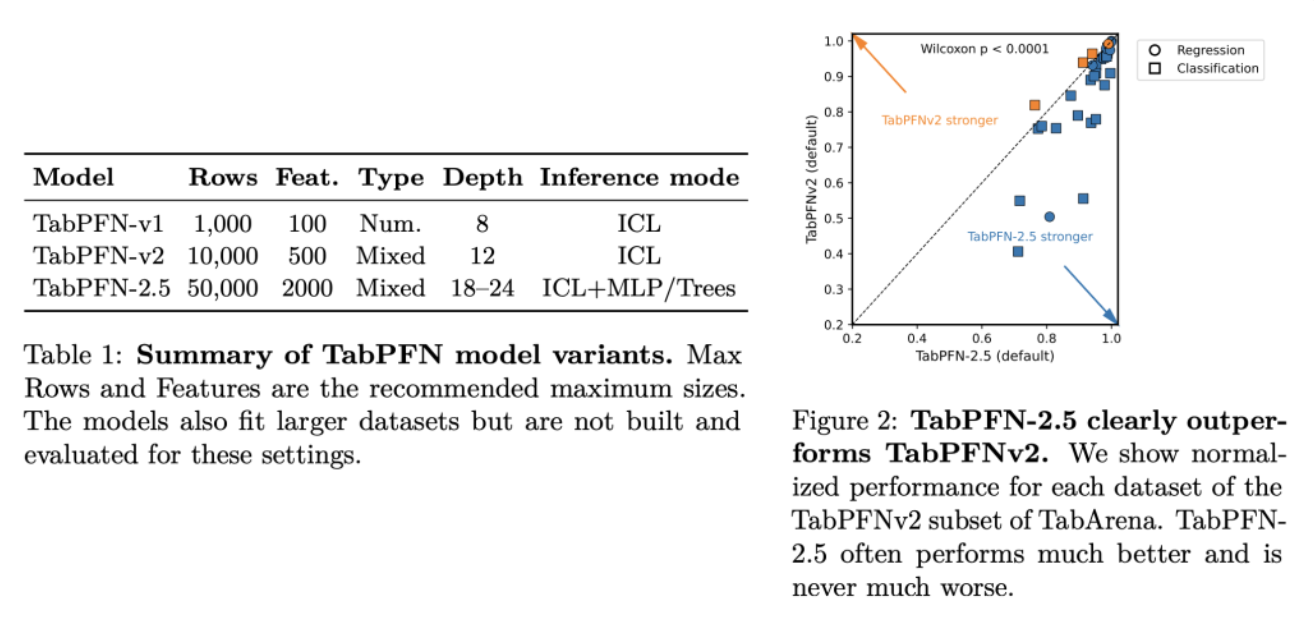
TabPFN在数百万个从结构因果模型(一种蕴含因果关系的先验分布)中生成的合成数据集上进行一次性预训练。 这使其学习到了一个强大的“元模型”,掌握了如何基于给定数据做预测的通用“算法”。
TabPFN模型就能像大语言模型(如ChatGPT)一样,通过分析给定的“上下文”(即训练样本),直接预测测试集的标签。整个过程无需针对该数据集进行任何训练或超参数调优。
RealMLP
RealMLP是一种为处理表格数据(Tabular Data) 而专门优化的改进型多层感知机(MLP)。它在2024年被提出,旨在挑战梯度提升决策树(GBDTs) 在表格学习任务中的主导地位。
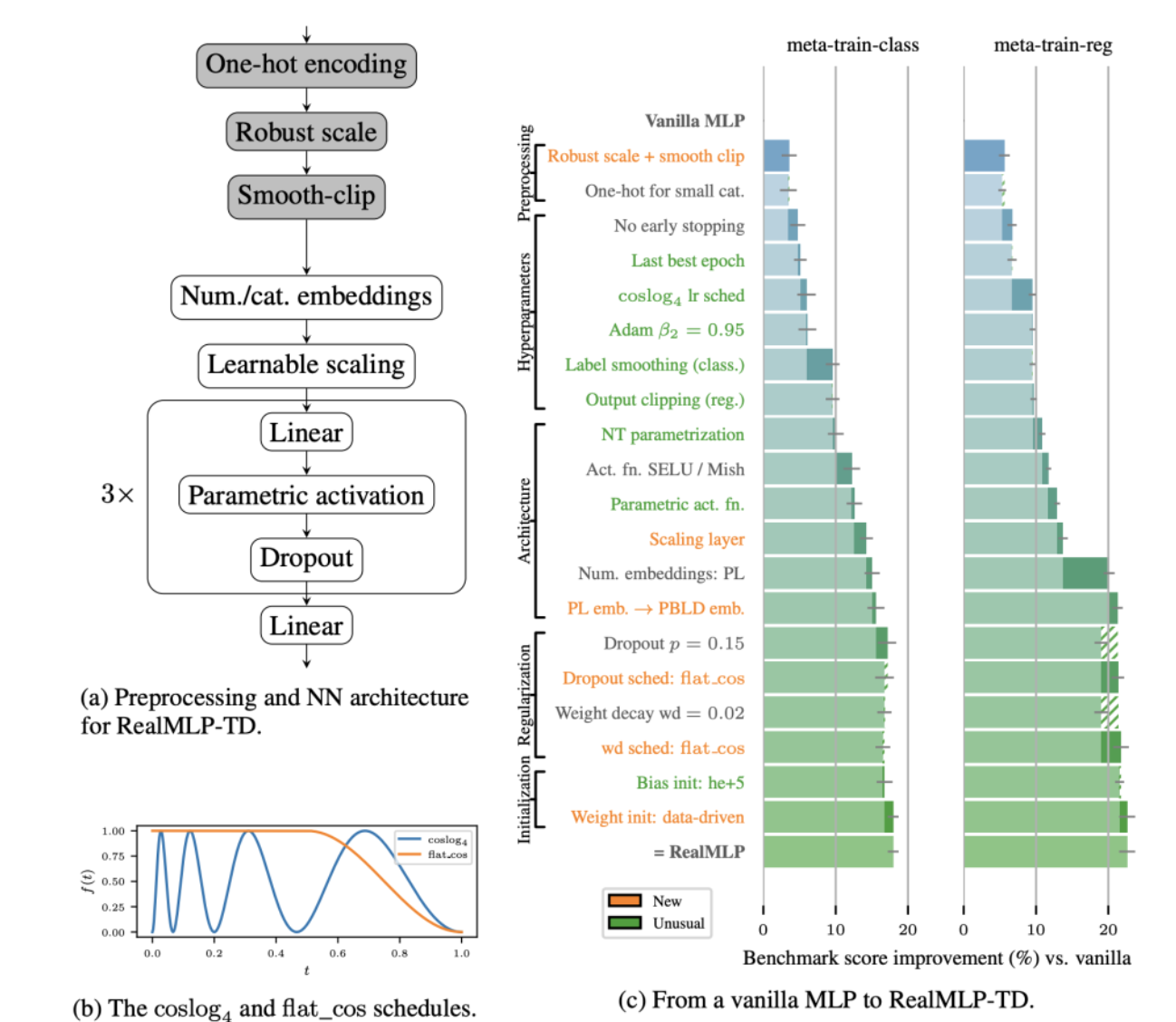
RealMLP的核心贡献并非提出一个全新的复杂网络结构,而是通过系统性、数据驱动的超参数优化,证明了一个设计良好、调参得当的经典MLP,完全可以在其目标领域达到顶尖水平。它旨在为研究者和实践者提供一个可靠、高效且无需复杂调参的强力基线。
DeepTables
DeepTables是一个开源的、专门为结构化表格数据设计的深度学习工具包。它的核心目标是简化深度学习在表格数据建模中的应用流程,让用户能通过几行代码快速构建高性能模型,以挑战XGBoost、LightGBM等传统集成树模型在该领域的统治地位。
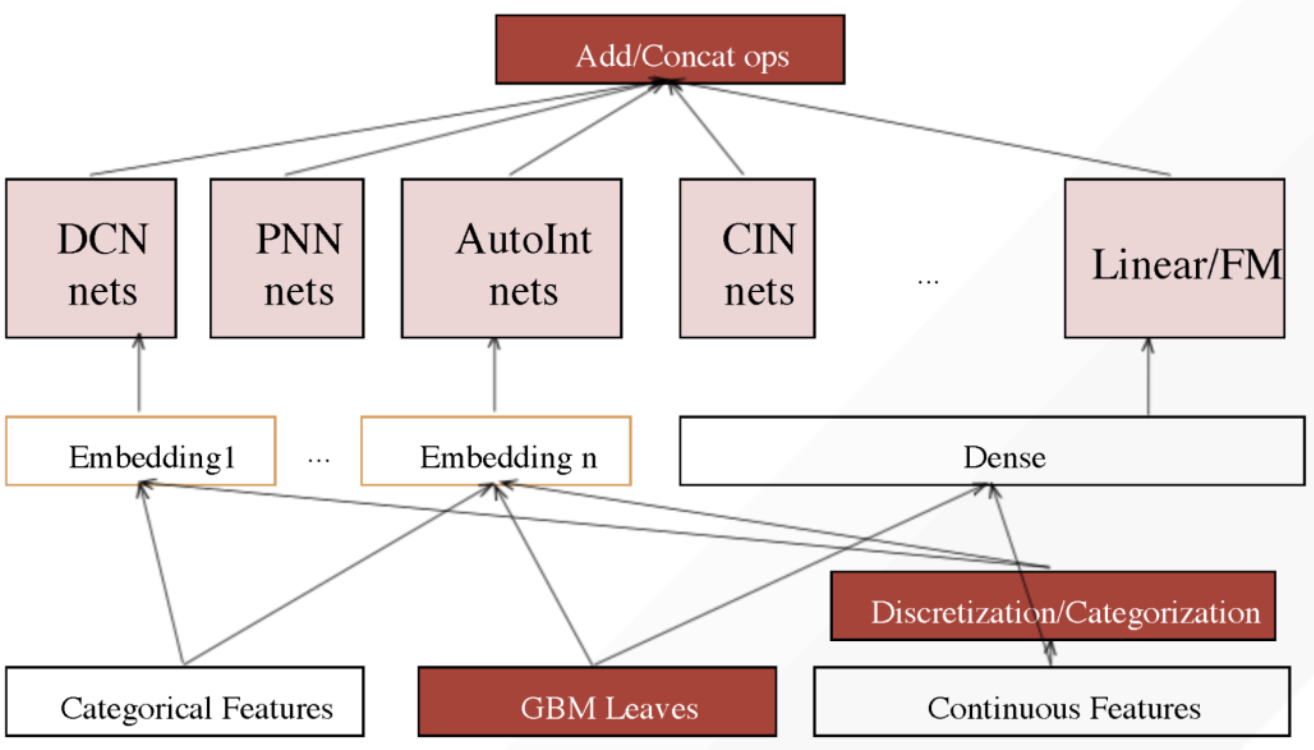
DeepTables并不特指某一个固定结构的神经网络,而是一个集成化工具箱。它通过复用和组合在CTR预估、推荐系统等领域被验证有效的先进网络结构(如DeepFM、PNN、AutoInt等),将它们转化为适用于通用表格任务的模块。
TabR
TabR是一个专门为表格数据设计的检索增强深度学习模型,它通过一个类似k-近邻的组件来利用训练数据中的相似样本信息进行预测。
TabR将目标样本和训练集中的候选样本(通常选择整个训练集或一个子集)通过一个编码器(如多层感知机MLP) 转换为向量表示。然后,模型的核心——检索模块——会计算目标样本与所有候选样本的相似度(通常使用L2距离而非传统的点积),并找出最相似的K个近邻。
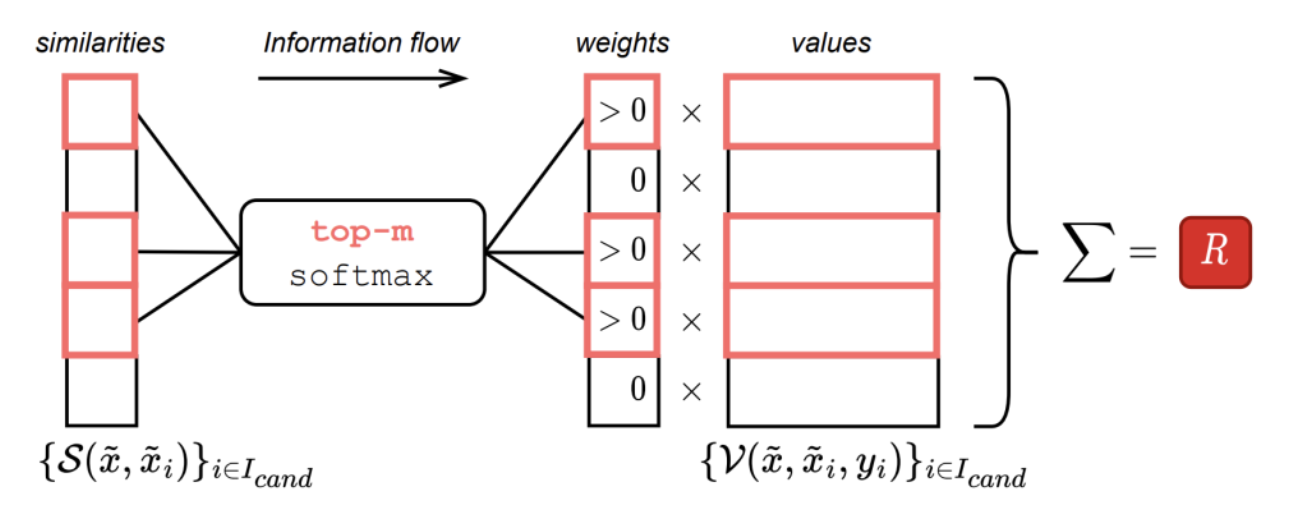
TabR模型不仅检索近邻的特征向量,还会利用它们的真实标签。通过一个注意力机制,对不同近邻的“价值”(由其特征和标签构成)进行加权求和,从而得到一个综合了局部相似样本信息的上下文向量
GANDALF
GANDALF的设计灵感来源于门控循环单元(GRU),它巧妙地将为序列数据设计的“门控机制”改造并应用于没有时序关系的表格数据中,以实现自动特征选择和特征表示学习。
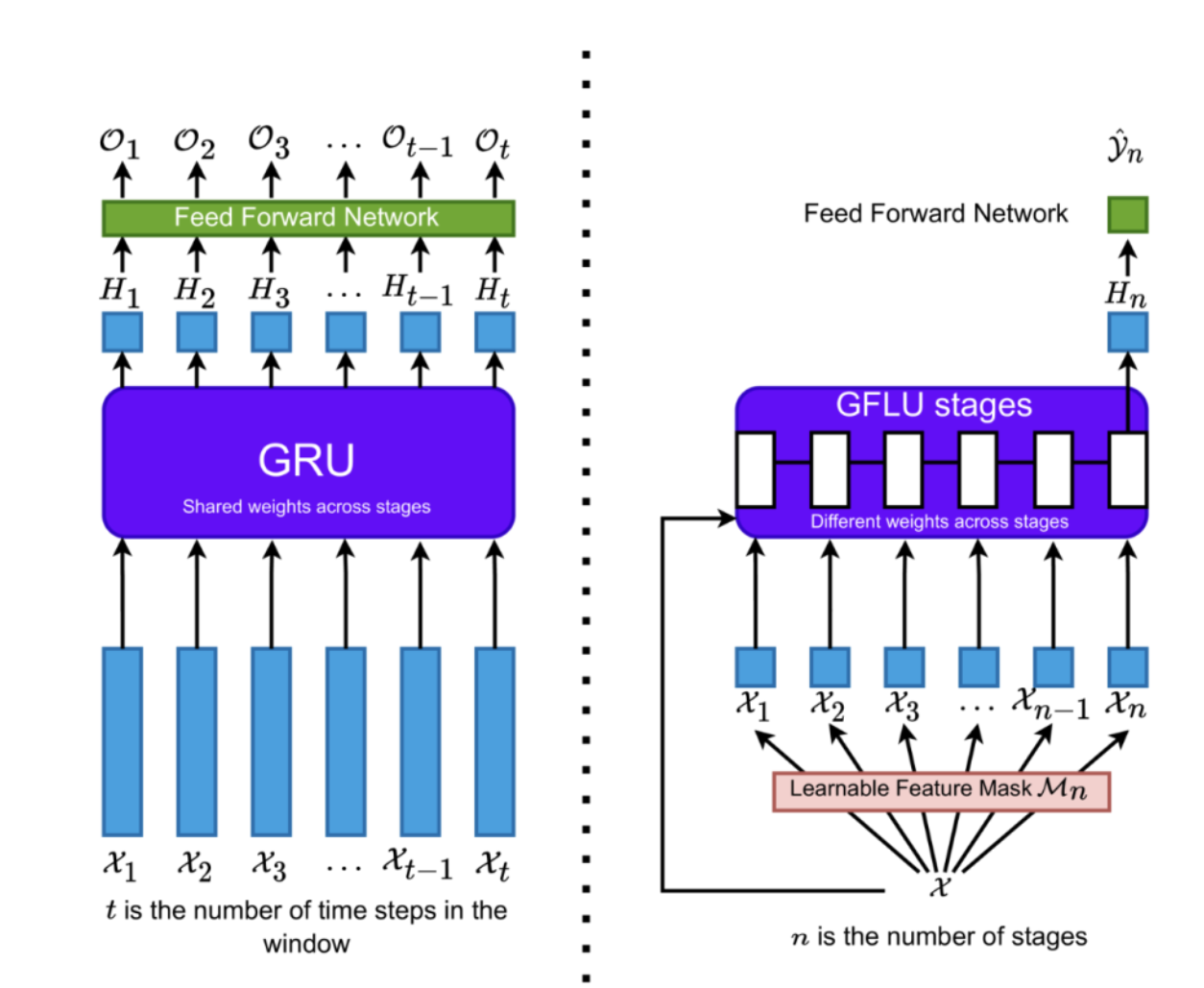
在每一个GFLU阶段 n,都有一个与特征维度相同的可学习特征掩码 M_n。这个掩码通过 t-softmax 函数(一种能产生稀疏性的加权softmax)生成,作用是对输入特征进行软选择,让模型能关注当前阶段最重要的特征子集。
多个GFLU像上图那样顺序堆叠。每个GFLU阶段都有自己独立的特征掩码和权重,这意味着不同阶段可以学习关注不同特征子集,并逐层精炼特征表示,实现层次化的特征学习。
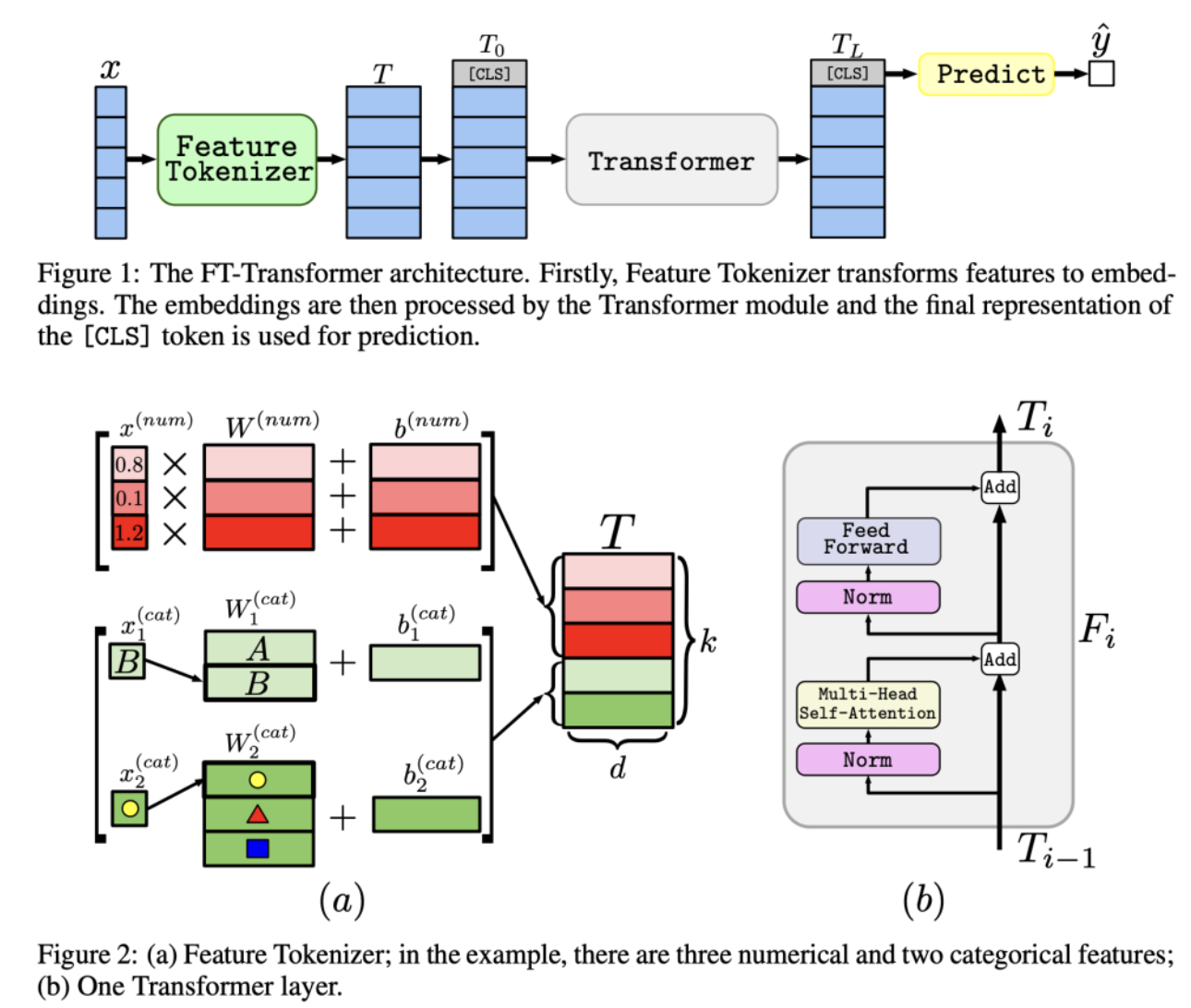
FTTransformer
FT-Transformer “Feature Tokenizer + Transformer” 首先将所有异构特征(数值特征和类别特征)转换为统一的向量表示(可以理解为每个特征变成一个“词向量”),其次将上一步得到的所有特征向量视为一个“序列”(但其中没有顺序关系),使用标准的、经过优化的Transformer层(采用 PreNorm 设计,便于训练)来处理这个“特征序列”。