文生图之Stable Diffusion(1)
Stable Diffusion模型原理
Stable Diffusion(简称SD)是一个基于latent的扩散模型,它在UNet中引入text condition来实现基于文本生成图像。
SD的核心来源于Latent Diffusion这个工作,常规的扩散模型是基于pixel的生成模型,而Latent Diffusion是基于latent的生成模型,它先采用一个autoencoder将图像压缩到latent空间,然后用扩散模型来生成图像的latents,最后送入autoencoder的decoder模块就可以得到生成的图像。
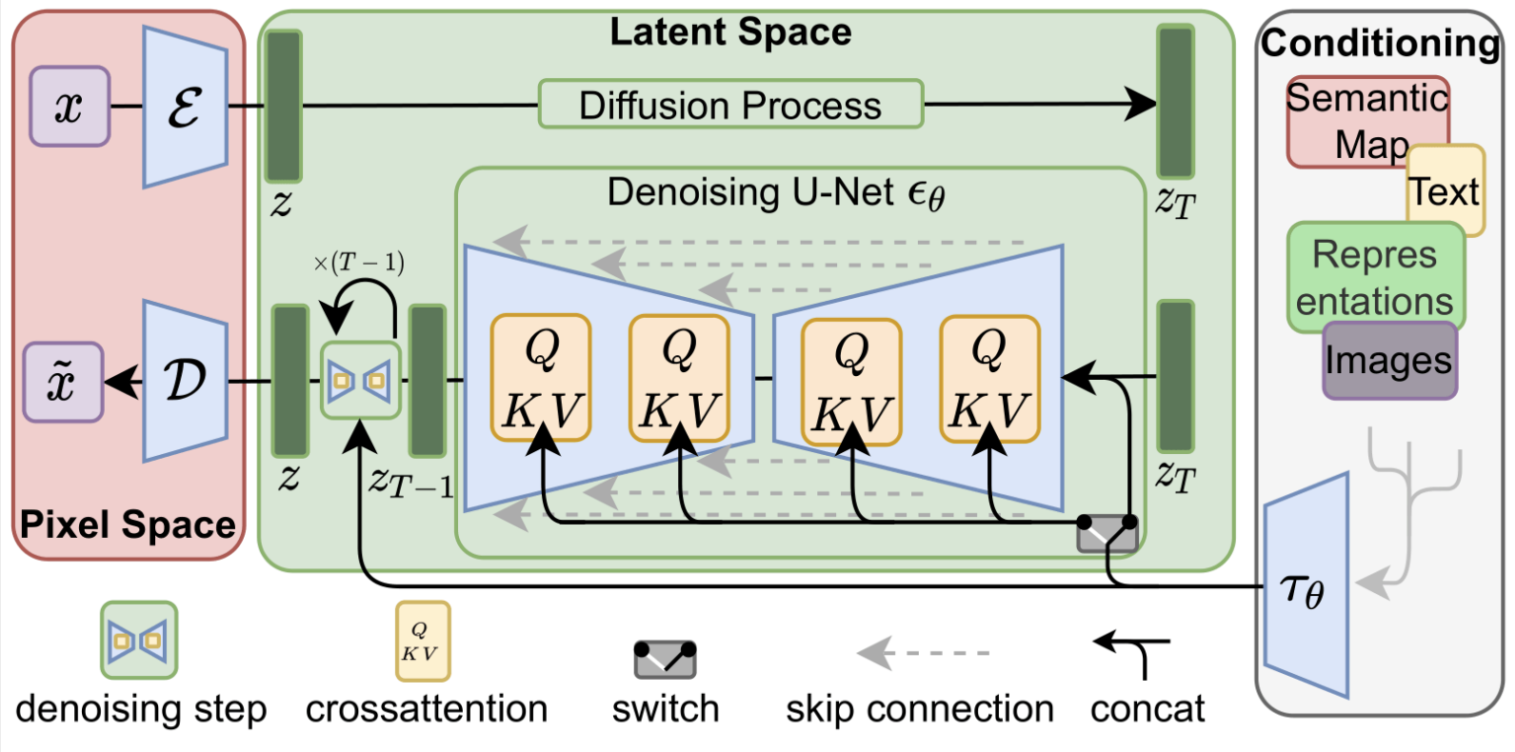
基于latent的扩散模型的优势在于计算效率更高效,因为图像的latent空间要比图像pixel空间要小,这也是SD的核心优势。基于pixel的方法往往限于算力只生成64x64大小的图像,比如OpenAI的DALL-E2和谷歌的Imagen,然后再通过超分辨模型将图像分辨率提升至256x256和1024x1024;而基于latent的SD是在latent空间操作的,它可以直接生成256x256和512x512甚至更高分辨率的图像。
Stable Diffusion模型结构
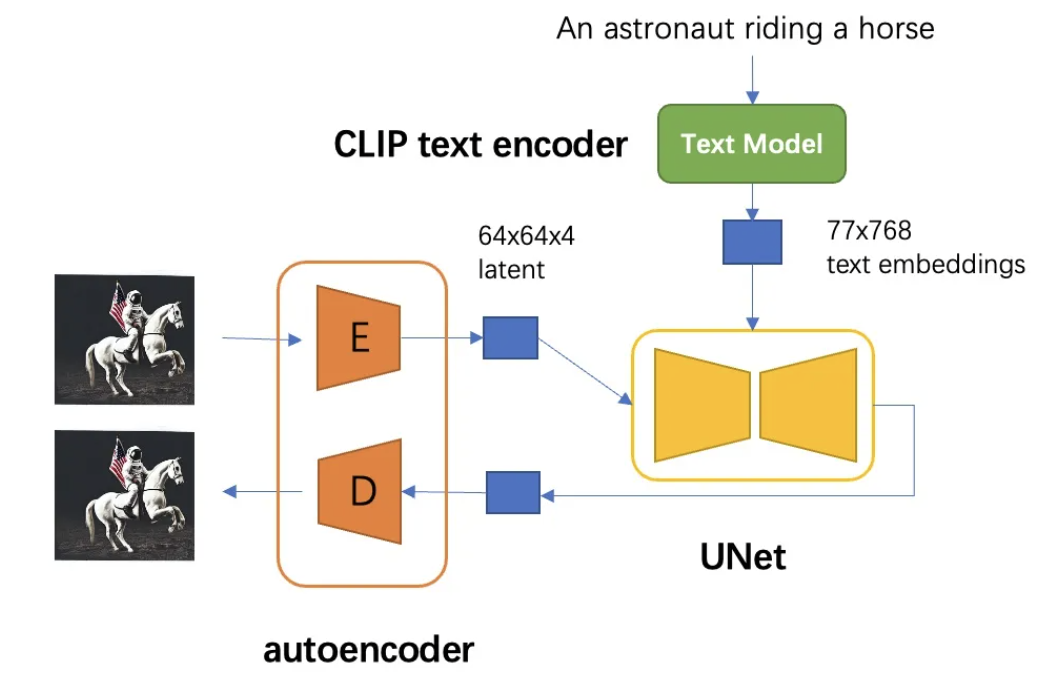
SD模型的主体结构如下图所示,主要包括三个部分:
- autoencoder:encoder将图像压缩到latent空间,而decoder将latent解码为图像。
- CLIP text encoder:提取输入text的text embeddings,通过cross attention方式送入扩散模型的UNet中作为condition。
- UNet:扩散模型的主体,用来实现文本引导下的latent生成。